
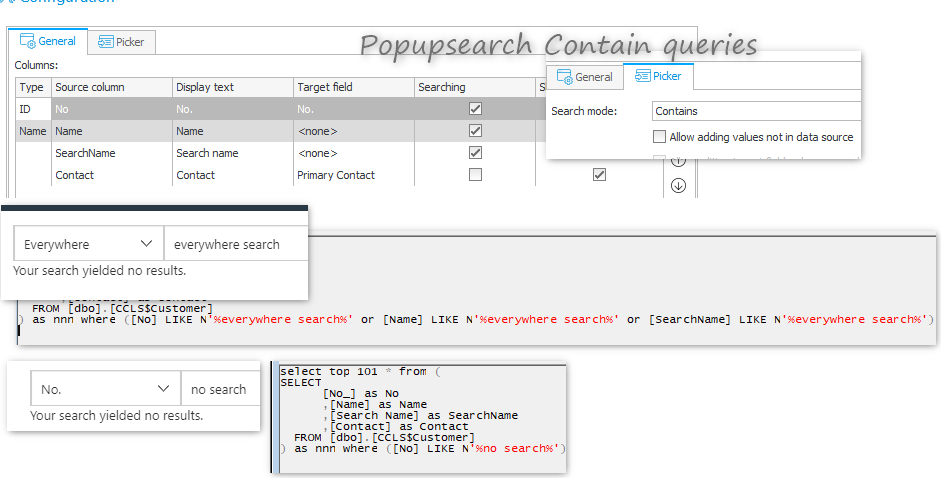
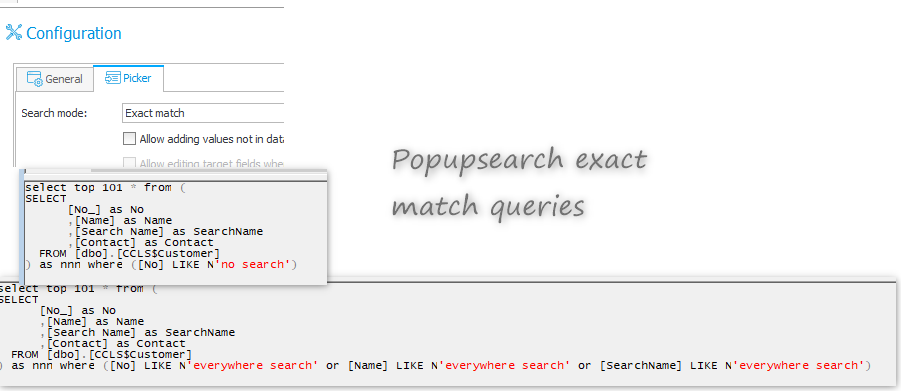
Currently selection attributes, such as picker, poll the database in such a way that LIKEs are always placed in the WHERE clause. The data that the database returns are then filtered according to the picker configuration (exact match, contains phrase, starts with).
In my company, we collect customer data from several CRM systems. For one of them, we have the customer's data materialized in the dictionary database. We query this data about 9 - 30 thousand times a day, on average one execution takes 3 seconds.
After changing the polling method from like to exact match (mediated by the SDK add-on), it turned out that the previous elapsed max of 95,000 seconds dropped to 10 seconds. This change reduced the load on the dictionary database, and thus relieved the entire database environment by about 27%. The 27% obtained will be immediately used by the main production base of BPS_Main.
According to the query plan, LIKE searches account for 98% of the query cost. The query with an exact match (=) is 2% of the query cost.
Due to the very high yield for the environment (large BPS instances), I propose to create a new type of selection attributes, where we give up filtering, and for columns intended for searching, we will add an additional search method parameter to the database: LIKE%, %LIKE%, exact match (=).
Optimization of questions to the database

Hi Dariusz,
I'm not sure whether I understand your requested change. Do you want to define the picker search mode per field?
If this is not the case, I don't see any necessary change. Depending on the selected search mode there's one specialized query against the data source, at least in case of a SQL database and if popup search window is used. If autocomplete is used, there are of course multiple queries.
Of topic:
It looks like you have a special database maybe you could add additional indexes on the database for the few columns.
Best regards,
Daniel


office@webcon.com
+48 12 443 13 90
+48 12 443 13 90