Service – the logic and operation
Applies to version: 2023 R1 and above; author: Łukasz Maciaszkiewicz
Introduction
The logic behind the execution of tasks by service is a multi-faceted and complex issue. When planning tasks, application designers are often unaware of the mechanisms and rules used by the service. To fill this gap, this article describes the elements affecting the sequence in which the service executes its tasks.
Content databases
The databases that store information on tasks to be executed are defined in the “Associated process databases” field (“System settings” → the „Service configuration” node on the left selection tree → “Services” → service name → the “Service” tab). The databases indicated here are processed by service in one of the following manners.
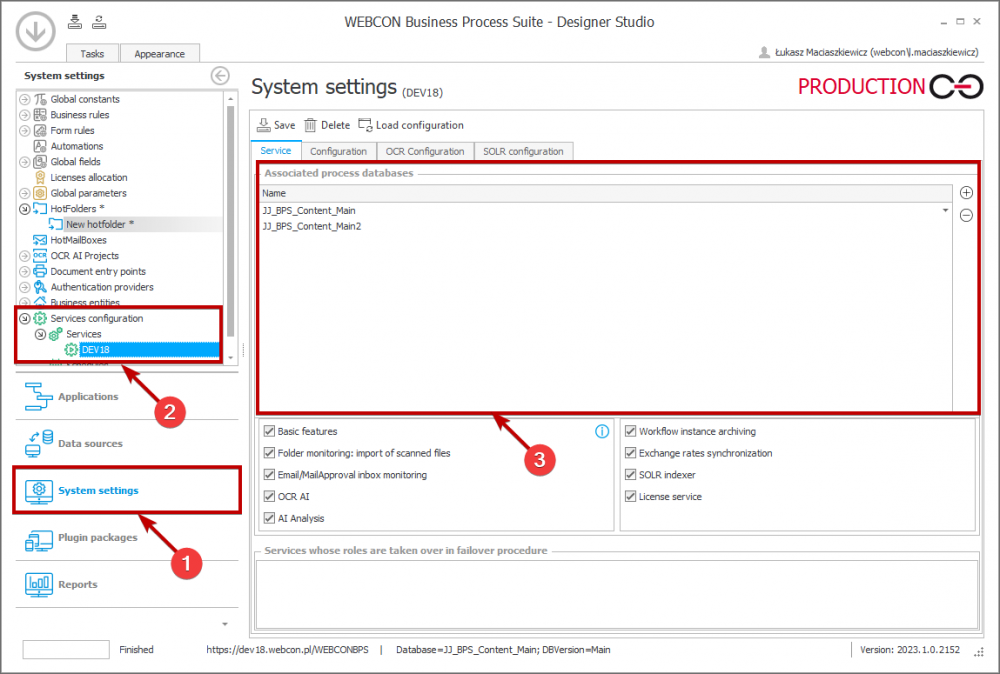
The „Associated process databases” field allows you to specify the databases to be processed by the service.
The sequence of task execution by service
The tasks executed by the service are generally grouped based on their running method. They can be triggered in three distinct ways:
- by queues,
- using an interval/schedule,
- with a command sent to service by an external environment that communicates with it.
All the three aforementioned methods operate parallelly. Their detailed description is provided further in the article.
Queues
There are several types of queues, each with its own threads that in most cases can be configured. This means that the number of the aforementioned threads can be specified for each queue in service configuration unless it is unconfigurable, as is the case with the “on-timeout” (1 thread) or cyclical (4 threads) actions. What is important, each thread operates independently, i.e. if you enable roles responsible for various queues in service and each role has four threads, then the threads operate simultaneously.
It is worth noting here that when a system has a processor whose number of cores is smaller than the number of the aforementioned threads, the operating system switches between the tasks in an attempt to execute them simultaneously. It is done efficiently enough to ensure that no task is neglected.
Simultaneous operation of threads means that there is no sequence per se in this case.
- Database processing
For databases, a master queue applies. It is a single query relating to all queues simultaneously executed by an SQL server. [Currently, the system logs some of the queries sent to the content database provided the “Debug” mode (“System settings” → the “Global parameters” node → “Diagnostic logging mode” → “Debug”) is enabled. It is not possible to view the queries sent to the configuration database]. Such a query starts along with service and is sent to all content databases according to a configured interval (10 s by default) to determine which queues can execute tasks. As the query relates to all databases, it returns instances available for processing in all queues from all databases. Then, the master queue informs respective queue threads (with tasks to execute) that queries assigning queue rows directly to a thread of a particular service queue can be executed. (Please note that the threads mean here application threads – not processor ones.) Subordinate queues execute a query assigning a task and then retrieve it.

Master queue operation diagram
The operation of the master queue is saved in the “Services activity” report (“Reports” → the “BPS WorkFlow Service” → “Services Activity”). (There are two databases presented in the below screenshot: “JJ_BPS_Content_Main Roles” and “JJ_BPS_Content_Main2 Roles”).
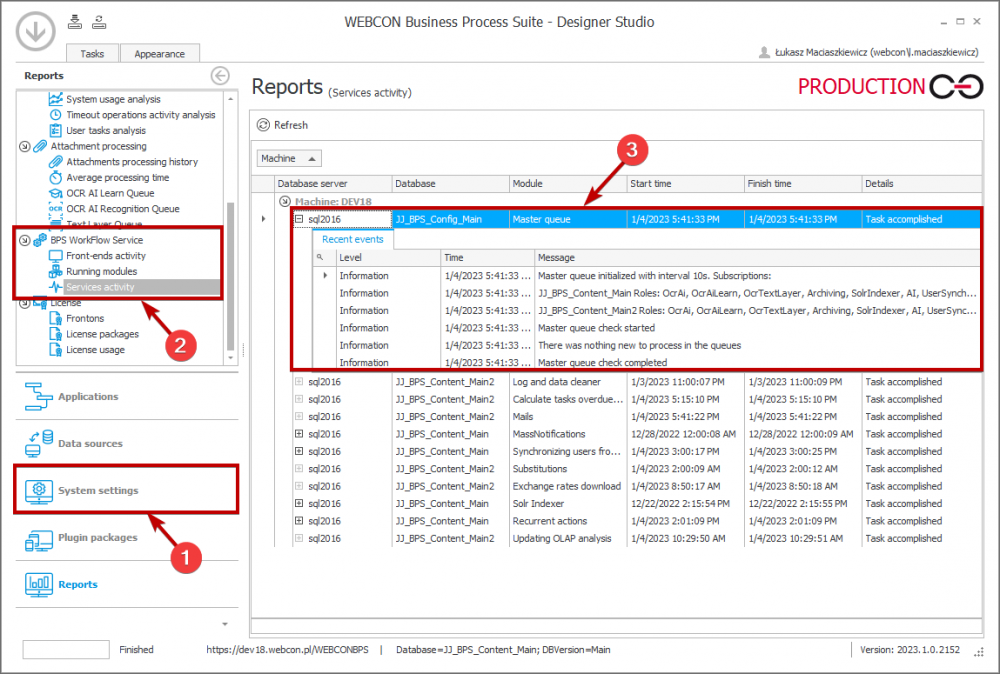
The “Services activity” report presents the activity of the master queue broken down by the managed databases.
It is worth noting that upon starting the service or a module the sequence of content database processing is drawn – this sequence then remains unchanged until the queue module is restarted. (You can infer the drawn sequence by monitoring the operations presented in the “Services activity” report). The queue thread sends a query to the sequentially first content database and if there is a task to execute in it, it executes it and then sends another query to the next database. Once all databases are served, the thread immediately sends queries to databases for the next potential tasks. However, if the query returns no task, then the thread waits for the master queue (10-second interval) and if it assigns some task to queues, then within a second the thread starts sending queries to databases in the manner described above.

Threads draw the sequence in which they query databases (in this case there are three databases available: A, B, and C).
To sum up, the primary function of the master queue is to inform queues on tasks found in content databases and to optimize the number of queries sent to databases.
- The number of threads and the sequence of task execution in queues
The number of threads is one of the factors that can affect the moment of execution of tasks in queues. Such a situation can take place if execution of certain tasks lasts long and the number of available threads is smaller than e.g. the number of cyclical actions (e.g. 4 threads and 5 actions). When this happens, if all 4 available threads are busy at the same time with processing 4 cyclical actions, the tasks under the 5th action are not executed until one of the threads is available again (finishes execution of tasks).
This is especially visible in the case of “On timeout” actions (executed by the service with the “Basic features” role enabled) where there is only 1 thread available. This thread must cover all the available content databases, so eventual longer execution of one “On timeout” action results in postponing execution of other action by respective time.
Bearing in mind the above mentioned principles, it should be noted that generally actions or tasks in a queue are executed in the sequence from the oldest to the newest in a given database unless there are some eventual priorities set (which is possible for certain actions or tasks, e.g. tasks relating to text layer which are executed in the following sequence: priority → date of creation [first the oldest ones] → the fewest attempts to execute).
Interval
An interval determines the time after which tasks are executed in a module not operating in queues. By default, this time is 60 s, but the duration can be changed by using the “Interval (seconds)” option (“System settings → the “Services configuration” on the right selection tree → the “Configuration” field → “Interval (seconds)”).
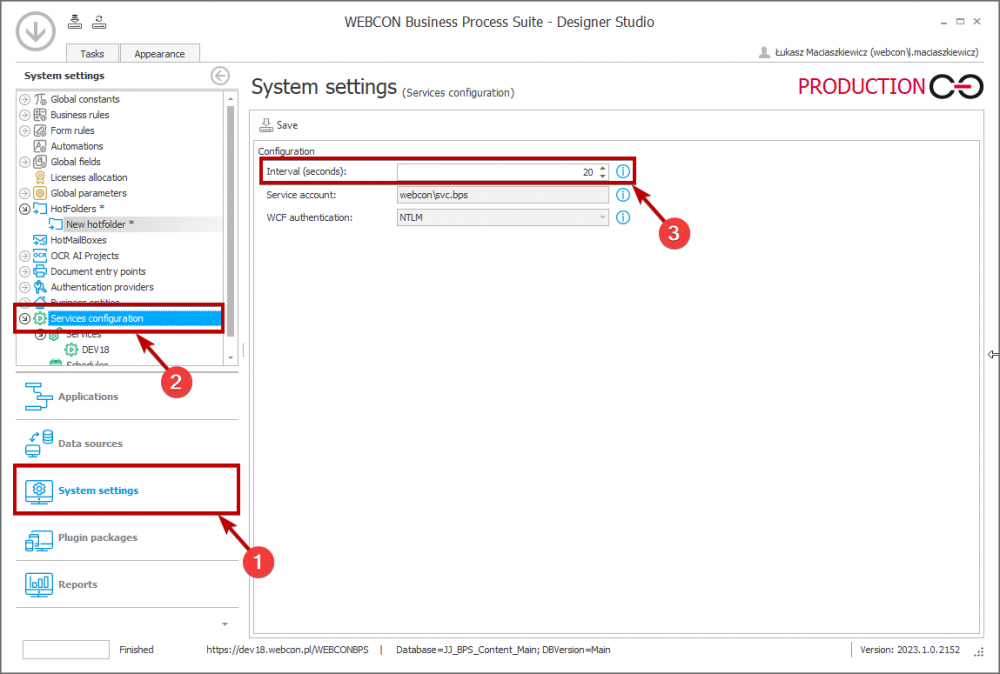
The “Interval (seconds)” option allows you to define the interval for service.
The interval applies to the below modules:
- Sending e-mails
- Folder monitoring: import of scanned files
- E-mail/MailApproval inbox monitoring
A special case is updating active task counters – this module has its own unconfigurable 30-minute interval.
Additionally, for the modules listed below, the system checks if according to the configured schedule it is time to run them:
- Mass notifications
- Substitutions update
- Exchange rates synchronization
- LogCleaner
- Updating OLAP analyses
- SOLR indexer
- User synchronization
- Awaiting text layer, Awaiting recognition, and Awaiting learning
Moreover, the service interval is also taken into account when transferring documents processed by a queue to the next step. It is best to illustrate this with an example where a text layer is created in a queue. In this case, the text layer is generated with an interval specified for the queue, but when a document including this text layer is transferred to the next step, e.g. for approval by a specified person, the service interval is applied (the text layer is not generated again).
- Interval operation
Modules are run after each interval simultaneously and each module has its own thread (i.e. one thread processes an individual module – after each interval the system creates an application thread for a given module). Within the modules, submodules can operate and handle specific databases. The sequence in which the submodules are run is drawn when a module starts. As a result, the databases are processed sequentially and once all tasks are executed and the interval time elapses, they are processed in the same sequence.
However, if execution of a task by a given submodule takes more time than the specified interval, this submodule (named “B” for this purpose) prevents execution of tasks by the next-in-line, eventual submodule (named “C” for this purpose) until it completes its own tasks. In such a situation, next interval is not started until submodules “B” and then “C” complete their tasks. Once the tasks are completed by all the submodules, they are all run after the next interval in the drawn sequence.
A complicated logic behind the interval is presented in the below diagram with a description.
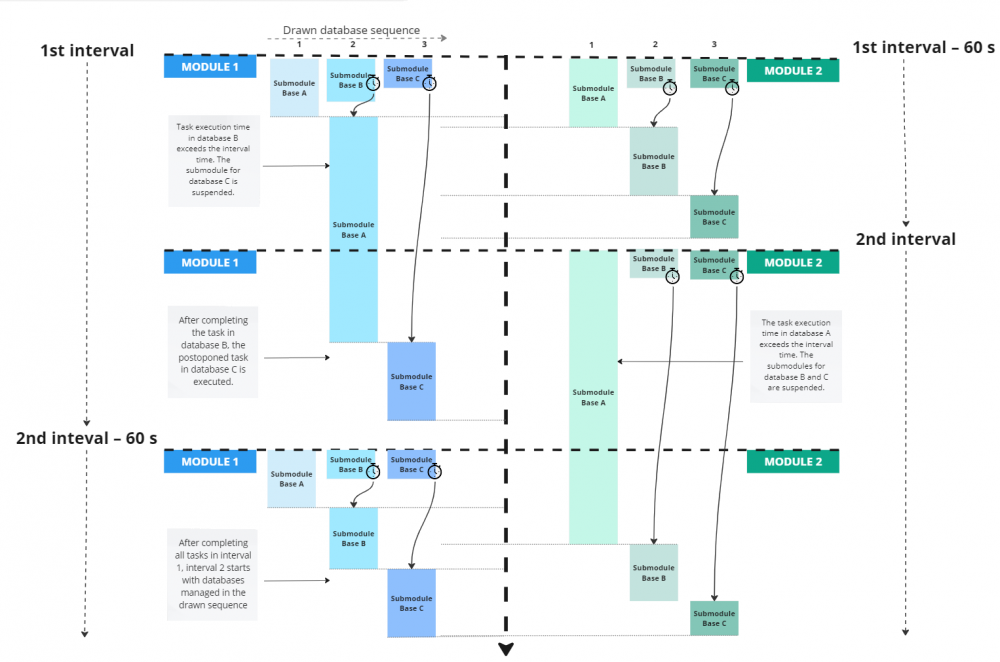
Diagram depicting service interval logic
The description below covers module 1 case only. Module 2 executes tasks in an analogical manner.
- When the first interval elapses, two modules are run (“Module 1” and “Module 2”) that include three submodules processing three databases: A, B, and C. In both cases, the database processing sequence drawn on starting the module is A, B, and C.
- In module 1, the submodule processing the database “A” is run first. It completes all its tasks.
- Then, the next-in-line submodule processing the database “B” is run, but it cannot complete its tasks before the interval elapses.
- Submodule processing the database “C” is halted and is not run in this interval.
- Second interval starts.
- The submodule processing database “A” is run. It completes all its tasks.
- The submodule processing the database “B” is not run and is skipped.
- The submodule processing the database “C” is run.
= at the same time the submodule processing database “B” executes the tasks it started in the previous interval. Once they are completed the submodule processing the database “C” (which did not execute tasks in the previous interval) also executes its tasks parallelly. (It can happen that two instances of the submodule processing the database “C” will operate.) The tasks are completed.
- In the third interval, once the submodules finish all their tasks, they are run in the drawn sequence of databases, i.e. A, B, and C.
- Hotfolders and hotmailboxes
Hotfolders and hotmailboxes are modules that execute tasks based on service interval This means that although it is possible to set priorities for individual tasks within hotfolders and hotmailboxes, they apply only within the content database and the sequence is essentially imposed by the service interval logic.
A demonstrative sequence of execution of tasks by the module “Hotfolders processing” handling two content databases is the following:
- the following hotfolders are defined:
- BPS_Content_Main database
- HotfolderBPS_a – priority 2 – number of files in the folder: 20;
- HotfolderBPS_b – priority 1 – number of files in the folder: 3;
- HotfolderBPS_c – priority 3 – number of files in the folder: 5;
- BPS_Content_Main2 database:
- Folder_mail_a – priority 10 – number of files in the folder: 5;
- Folder_mail_b – priority 3 – number of files in the folder: 42
- Folder_mail_c – priority 5 – number of files in the folder: 8;
- BPS_Content_Main database
- there are two submodules in the “Hotfolders processing” module that process separate content databases: BPS_Content_Main and BPS_Content_Main2. These submodules are run in the sequence drawn on the service start-up – for the purpose of this article this sequence is first BPS_Content_Main2, and then BPS_Content_Main;
- once the service interval elapses (60 s by default) the submodule processing the “BPS_Content_Main2” database is run:
- 42 files stored in the “Folder_mail_b” hotfolder (priority 3) are processed;
- 8 files stored in the “Folder_mail_c” hotfolder (priority 5) are processed;
- 5 files stored in the “Folder_mail_a” hotfolder (priority 10) are processed;
- once all the tasks in the “BPS_Content_Main2” content database are executed, the submodule processing the “BPS_Content_Main” content database is run:
- 3 files stored in the “HotfolderBPS_b ” hotfolder (priority 1) are processed;
- 20 files stored in the “HotfolderBPS_a” hotfolder (priority 2) are processed;
- 5 files stored in the “HotfolderBPS_c” hotfolder (priority 3) are processed;
- all the tasks in both content databases are completed. The submodules are run again when the next interval elapses.
Note the number of files stored in individual hotfolders that are processed. Those files are processed one by one and, what is important, all of them must be processed for the submodule to move to the next hotfolder. If a submodule cannot process all files until the next interval elapses, it is not run as long as it does not finish the uncompleted tasks. The aforementioned number of files can be defined using the option “Limit of files to be processed in iteration” (“System settings” → the “HotFolders” node → hotfolder name → the “Advanced settings” tab → “Limit of files to be processed in iteration”). It is also worth mentioning that in the case of hotfolders with the same priorities the sequence of execution is random.
The above-described logic, including the operation of priorities, also applies to hotmailboxes.
Commands from external environments
Service can execute tasks following commands sent from an external environment. Such unidirectional communication is handled by the “WCF Service” module whose operation can be seen in the “Running modules” report (“Reports” → the “BPS WorkFlow Service” → “Running modules”). Depending on the type of task, it is executed immediately irrespective of other executed tasks or alternatively queued.
An example of the first type of task is e-mail sending. Such a task is executed concurrently with other tasks executed by the service, immediately after receiving a command from an external environment. On the other hand, an example of a queued task is synchronization – if such a task cannot be executed immediately, it is queued.
“Configuration of sending e-mails” – an example of a task executed following a command from an external environment.
+48 12 443 13 90